This article is brought to you by Datawrapper, a data visualization tool for creating charts, maps, and tables. Learn more.
A gap on the map: How busy are the rails?

Hi, Inga here. Are you as interested in rail transit as I am? I usually work on Datawrapper’s platform code (not related to the train platforms!), but this week I’ll be sharing a map of public transport frequency in Berlin.
I’m a big fan of trains and maps. And since I live in Berlin, the city’s transit system is a natural part of my life. For a long time, I have been thinking that there’s something missing in the maps I see around.
Rail transit frequency: The missing map
There are official network schemes, but those are abstract and disconnected from geographical reality. There are official maps hanging on the stops and stations, but they typically only depict a relatively small area, show everything in uniform lines, and are full of map details while only showing transport in muted colors.
The transit layer of Google Maps is useful, but it shows all tram tracks in uniform lines regardless of how many routes pass through, and it groups them in a strange way. (For example, the S45, S46 and S47 trains are displayed as a single line but the S41 and S42 trains on the Ringbahn, Berlin’s Circle Line, are displayed separately despite serving the same line in opposite directions.) Organic Maps, a popular open-source map app, also offers a “transit” layer, but it has its limitations. It’s only visible at certain zoom levels, does not display trams at all, and the locations of some features are incorrect.
Most importantly, none of these maps show the frequency of service on each line. There’s no way to distinguish between the route or line that’s serviced every 3–4 minutes and the route that’s serviced only once every 20 minutes. This data can be really interesting! So I took the matters into my own hands.
First draft
One useful thing to know is that almost all urban transit in Berlin works in 20-minute cadence during the day. (A train will come every 20 minutes, or every 10, or 5, or 6/7/7, or 5/5/10... You get the idea.) So we can represent it as a network of "lanes," or the pairs of trains or trams passing every 20 minutes in each direction.
I've decided to use data for off-peak daytime (between the morning and evening rush hours), because they are the most representative. If you were to go to a tram or train stop at some time during the day, these are the frequencies you would most likely see.
Now, to improve and simplify the scheme, lanes could be arranged to not have any intersections, except for those with bridges where tracks meet but do not merge.
For example, the S-Bahn’s frequency scheme could look something like this:

Generating a detailed map like this would be difficult and time-consuming. Since it’s my first time creating a map, I decided to go with the second-best thing: instead of showing a varying number of lines, I use varying line thickness. The thicker the line, the more trains or trams pass in 20 minutes (one pixel = one lane = one pair of trains in opposite directions). For example, a typical U-Bahn segment would have a thickness of 4 pixels — 4 pairs of trains pass every 20 minutes, so you can catch a train in each direction every 5 minutes in off-peak hours.
I've decided to only display trams and U-Bahn and S-Bahn trains. Regional trains run in a 2-hour cadence, which would force me to work with unwieldy large numbers, and they are not used as urban public transit very much. Their tracks run parallel to S-Bahn tracks in a lot of places but have fewer stops, which would only make things more confusing. (For example, there is not a single regional stop between Ostkreuz and Erkner, where there are nine S-Bahn stops on the same stretch.)
Final version(s) of the map
Here is what I've got. This is the entire Berlin network:
And this is a zoomed-in view of the eastern part of the city — to this day, most trams are in the east, because West Berlin demolished most of its tram network to free more space for cars, while East Berlin even constructed new routes:
And this is the center, where transit routes are densest:
Behind the scenes
If you like my map and would like to recreate it for your own city, you can find a step-by-step guide with all the details, including the process of uploading geocoded data into Datawrapper, below.
Preparation
First, we need the data. It can be useful to have a cheat sheet to consult in case one’s memory of the train frequencies in some segments is hazy (for example, I don't clearly remember most of the parts of the tram network in Schöneweide and Köpenick, or to the west of Schönhauser Allee), as a way to double-check that the data is correct.
For this, I created a spreadsheet with the following information:
- On the first sheet, I entered all the raw data with frequencies for every route, to have it at hand (e.g. for S1: 2 pairs of trains per 20 minutes between Potsdam and Frohnau, 1 pair of trains between Frohnau and Oranienburg). The schedules can be downloaded from https://www.bvg.de/de/verbindungen/linienuebersicht (for every line, there is a Fahrplan PDF).
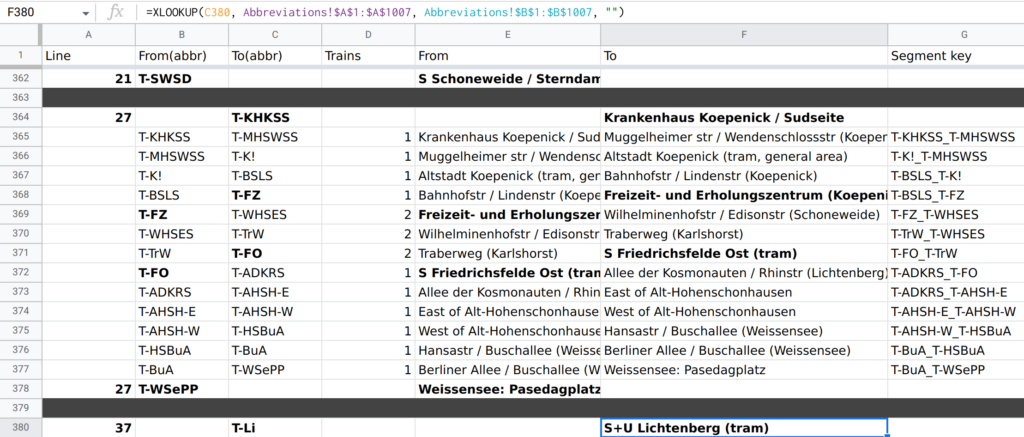
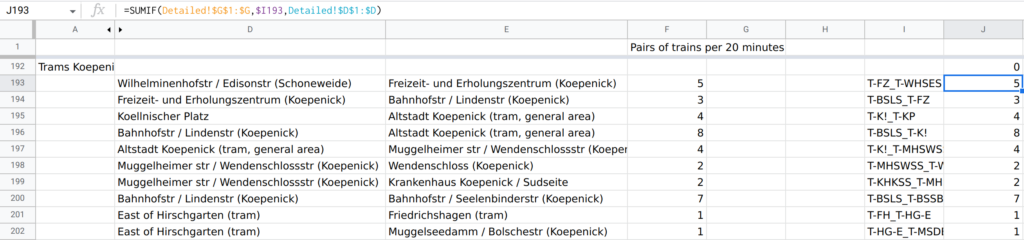
- Then, I identified all meaningful stations and other points in the network with changeable frequencies (because of branching, or because it is a terminus for some trains). So I have, for example, “Ostkreuz-West” (where S9 joins the Stadtbahn), "Ostkreuz-South" (where S9 joins the Ringbahn), and "Ostkreuz-East" (where S3 branches off S5, S7, and S75), but Friedrichstraße is not on this list, because while it is an intersection, there are no branches, and no trains terminate there. This produced 153 points. I've also added a short key code for every point for simplicity (e.g. T-WSePP for Weißensee Pasedagplatz tram stop). To make sure there are no bugs in this list, I configured it to highlight duplicate names or keys in red.
- Then, I identified all segments with no changes in frequencies, listing key codes for their start and end points, using two additional columns to expand these codes into point names from the previous sheet, and a third column to construct a key code for this segment (a combination of key codes for its start and end points in alphabetic order). To make sure there are no bugs in this list, I configured it to highlight rows with incorrect key codes and duplicate entries (regardless of their order) in red. This sheet had 209 rows.
- For every route from the first sheet, I split them into segments from the previous sheet, and highlighted any rows which do not refer to a segment listed on the previous sheet, do not start where the previous segment ended, or do not end where the next segment starts, to avoid bugs.
- And finally, by combining the third sheet with the fourth, I produced a dataset of all segments and their aggregate frequencies across all routes.

How I built the map
There is a useful website https://overpass-turbo.eu/ which helps you find all OpenStreetMap features for any given filters in a target area (and figuring out the filters is easy with the "Query map features" item in the context menu on https://www.openstreetmap.org/).
I originally made the mistake of using the "route=subway" filter, which produced 18 polyline features, one for each U-Bahn line in each direction. The problem is that these polylines also include station platforms (so they would be very jiggly and unclean), and that, while it would be manageable to split them around Nollendorfplatz / Wittenbergplatz, it would be much more difficult to do the same for S-Bahn and trams.
Instead, I used the "railway=subway" filter ("railway=tram" for trams, "railway=light_rail" for S-Bahn plus "construction:railway=light_rail" for Lichtenrade-Blankenfelde section which is now being rebuilt as part of general Dresdner Bahn construction works). This produces all tracks divided into their own stretches.
There are recommendations to "simplify" the exported data, but this should only be done at the very end, if necessary at all. Otherwise, since the exported data contains thousands of track stretches, they will be "simplified" individually, which will not affect the output size very much but might significantly decrease the quality of long and winding track stretches.
Another thing to keep in mind is to only use a single track for every segment. Using several tracks will produce several lines, which might blend into what will look like one line at small zoom levels or on low-res screens, but will split into several on higher zoom levels, adding visual clutter. Even when the lines blend into one, the resulting line will be thicker than individual lines (because it actually is a combination of two individual lines centered on different tracks), and its thickness will fluctuate depending on the distance between tracks (or their number), making the entire chart less polished. I learned this the hard way.
Choosing the right track is a separate problem. Ideally, the result should represent the "lanes" as described at the beginning of this post. For adjacent segments without branches this can mean alternating between tracks, e.g. using the eastern track for the S-Bahn Waidmannslust-Frohnau segment, and the western track from Frohnau to the point where S8 joins before Hohen Neuendorf. That way, the thicker line and the thinner line are centered on different tracks, and their western edges are closer to each other (ideally one being a direct continuation of the other) and eastern ones further apart than if they were centered on the same track. I learned this the hard way, too.
Finally, I hyperfocused on mapping these exported track stretches into my track segments on https://mapshaper.org/. To do this: click on a mouse pointer, "Select features", select track stretches for another network segment, "Split", switch the layer back to the main one, and repeat. To split a single track stretch when needed, draw a closed polygon on https://geojson.io/, export it into geojson, import it into mapshaper, open the console, execute divide -source=POLYGON_LAYER_NAME -target=LAYER_WITH_TRACKS, and get every polyline in that layer that was crossing any polygon divided into two parts, one inside the polygon, another outside.
(I also learned a lot in the process! Did you know that the German Wikipedia article on Kniprodestraße has one word for every 15 centimeters of the street’s length? Or that two additional tracks on the platforms of U5 Alexanderplatz were built for the new U-Bahn line that was planned a century ago to run to Weißensee, underneath what is now the M4 tram?)
After this is done, for every layer with a network segment: execute style stroke-width=NUMBER_OF_TRAINS_FOR_THIS_SEGMENT, display everything except for the main layer (containing everything that wasn't used in segment layers), and if everything looks OK, export the results (to have a backup copy of all these individual stretches, just in case), then remove unused layers, execute dissolve copy-fields=stroke-width target=* to merge all polylines into one polyline for each remaining layer while preserving their widths, execute merge-layers target=* to get them into a single layer (so that they can be exported into a single GeoJSON), and execute style stroke=#COLOR. In the end, I created 17 polyline features for U-Bahn (from the original 1256), 55 polyline features for S-Bahn (from the original 3051), and 103 for trams (from the original 2365), and I decided to display them in their customary shades of blue, green and red.
Now all that remains is to import these GeoJSON files into Datawrapper. There is a limit which only lets you import up to 20 line markers at once. But thankfully, Datawrapper merges all separate polyline features with the same attributes into one line marker, so there is, for example, only one for "all segments of tram network with two trams per 20 minutes" and there are only 26 line markers total.
That's it!
I’m not sure if the way I’ve done it is the best way (or even the right one) because this is my first experience working with anything map-related! But I hope you find it interesting to explore the results.
And next time you’re out walking in the woods on a winter day, you can check this map and make sure you don’t freeze too long waiting for a train home!
That’s it from me! Next week you’ll hear from our co-founder and CTO Gregor.



Comments