

What to consider when choosing colors for race, ethnicity, and world regions
October 9th, 2024
11 min
This article is brought to you by Datawrapper, a data visualization tool for creating charts, maps, and tables. Learn more.
…and how to customize them.

How should the text appear in your data visualizations? The possibilities are endless: There are millions of typefaces out there (Arial, Times New Roman, Lato, …) belonging to different categories (serif, sans-serif, condensed, wide, …). Many of these typefaces come in different fonts (thin, bold, …). And then they are so many extra ways of adjusting them (uppercase, size, color, …).
The short answer: When in doubt, set your text in a font that’s easy to read. Easy to read is everything that readers are used to. On the web, that means sans-serif, neither overly narrow nor wide, regular (instead of bold or thin) text set in sentence case, in a size that’s big enough to read, and in black or almost black. This article explains all these options — and shows how ignoring this advice can set your visualization apart from others.
Choosing a font
01 Use sans-serif typefaces.
02 Use a font with lining and tabular numbers.
03 Use a font with all the symbols you need.
04 Use bold fonts only for emphasis.
05 Avoid very thin fonts.
06 Use neither overly narrow nor overly wide fonts.
Adjusting the font
07 Use text that’s big enough.
08 Use a high-contrast color for most text.
09 Use uppercase text sparingly.
Let’s start:
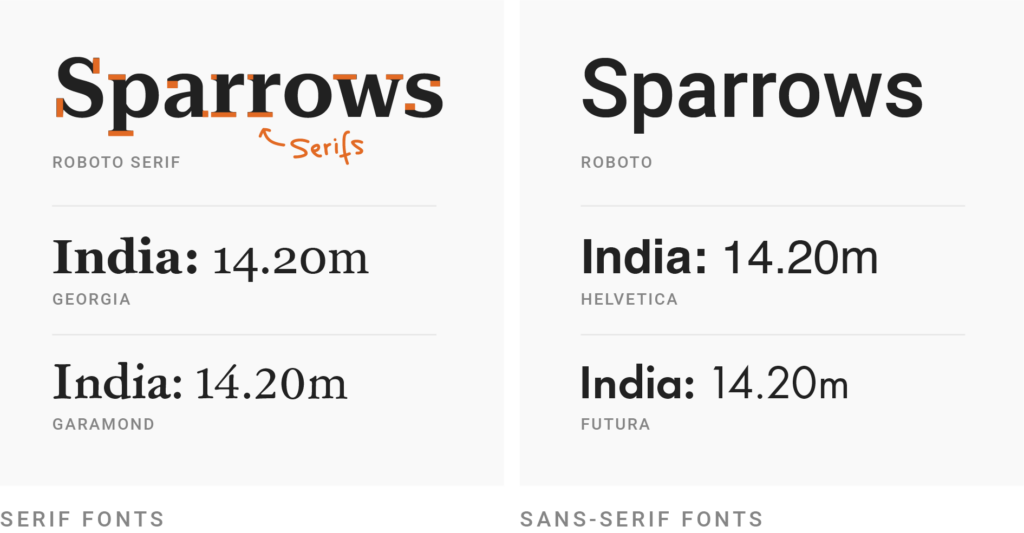
Serif typefaces (like Times New Roman or Georgia) bring you into a reading flow — that’s why they’re great for setting long texts like novels or newspaper articles. For data visualizations, sans-serif (”without serifs”) typefaces are most often the better choice. They look cleaner and are often easier to skim than serif fonts, especially when it comes to numbers. Our free Datawrapper visualizations, for example, use the sans-serif typeface Roboto. Changing the fonts – including size, placement, color, etc. – in Datawrapper is possible with a custom theme.
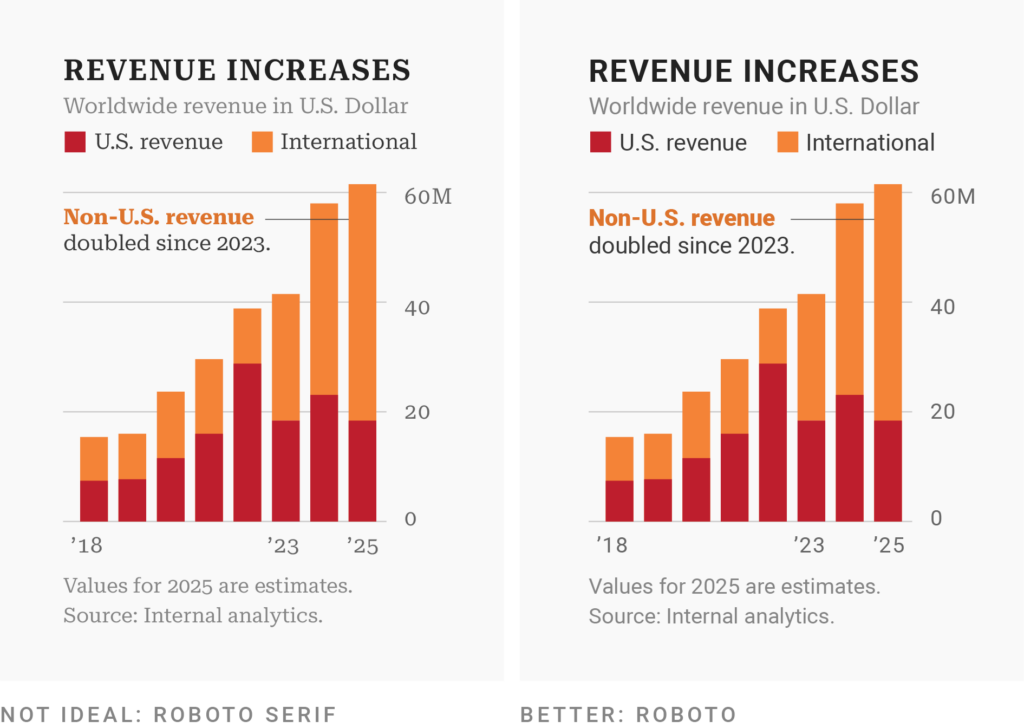
Most data visualizations use sans-serif typefaces — like all charts from The Economist and Bloomberg:

While serif typefaces are rare in data vis, they do exist. Serifs look a bit more classy, traditional, and serious/professional than sans-serifs and can set a visualization apart from others out there. Most often, serifs are only used for visualization headlines:


But some data vis designers use serifs for labels and numbers, too:

If you browse a font catalog like MyFonts, Adobe Fonts, or Google Fonts, you’ll notice more categories than just serif and sans-serif: They also let you choose slab serifs, script fonts, handwritten-looking fonts, and monospace fonts. They’re all rarely used in data visualization — but here are a few examples:


When in doubt, use a sans-serif typeface for the text in your visualization. Roboto, Lato, Open Sans, Source Sans Pro, and Noto Sans are all good options and free to use. None of them will make your visualization stand out, but all of them will be readable and pleasant to look at.
If your organization uses a lot of serif text, consider using that same serif typeface for the title of your visualizations to make them more recognizable.
👉 Read more: Choosing Fonts for Your Data Visualization by Tiffany France
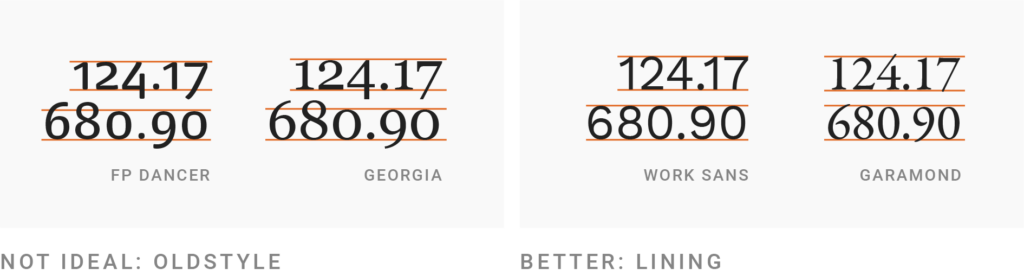
Different fonts have different ways to display numbers. There are two distinctions: First, between so-called oldstyle figures and lining figures. Lining numbers “line up”: They’re all the same height. Oldstyle numbers go below and above the “line.” They’re common in serif typefaces like Georgia and beautiful to look at in a paragraph, but hard to read in a table, tooltip, or as an axis tick. For your data visualizations, use fonts with lining figures.
The second distinction is between proportional and tabular figures:

Tabular figures are, as the name implies, great for tables. That’s because every number is the same width. It’s easy to see instantly how many figures a number has, because a 124.17 will be the same length as a 680.90, but shorter than a 1,111.17.
So why do proportional figures exist at all, you ask? It’s because they’re nicer to look at in a paragraph than tabular figures. An 8 deserves more width in text than a 1, just like a W deserves more space than a J. But for most of your data visualizations, use tabular figures.
As in the examples above, oldstyle figures are almost always proportional and tabular figures are always lining figures. All the sans-serif typefaces I mentioned (Roboto, Lato, Open Sans, Source Sans Pro, and Noto Sans) come with tabular, lining figures. You can also use font catalogs like Adobe Fonts to filter by “default figure style.”
👉 Read more: Finding the best free fonts for numbers by Samantha Zhang
👉 Read more: Fonts for Complex Data by Jonathan Hoefler
Do you create a lot of tables and want to go one step further? Then consider fonts with tabular, lining figures that are multiplexed (also called duplexed or uni-width). Multiplexed means that each character and figure uses the same width in each font weight. Bold text set in most fonts is wider than the same text in a regular font style. Multiplexed fonts don’t have that quirk, which makes them great to highlight numbers in tables:

To play around with a multiplexed font, you can download and try out Recursive from Google Fonts. For more multiplexed fonts, visit the article Uniwidth typefaces for interface design by Lisa Staudinger.

Besides the figure style, the font you choose should also have all the characters (typographers call them glyphs) you need. Do you need special characters for specific languages (ü ß é)? Are you using lots of currency symbols ($ € £ ¥)? How about math symbols (+ ÷ × = %)? ® and ©? Reference marks (* † ‡) or superscripts for footnotes (¹ ² ³)? Confirm they all exist before you adjust your whole visualization to a font.
All these glyphs need to be drawn by a type designer — often by hand — so don’t take for granted that they come with every cheap font. For example, superscript numbers (¹ ² ³) are not simply smaller numbers. Good type designers draw a ² so that it’s more legible than a simply size-reduced 2.
Don’t just check that all needed glyphs exist, but also that you like how they look. Do the % signs in the Source Code and Recursive fonts make you happy, or are they too experimental for your needs?
👉 Read more: Checklist for choosing data viz typefaces by Diana MacDonald

Most typefaces come with fonts for different weights, like thin, light, regular (= the default, also called normal), medium (= a slightly bolder regular), bold, and black (= extra bold). Webfonts often use numbers for these weights, where 400 is regular and 700 is bold.
Bold or even “black” text feels more self-confident and attention-grabbing than regular font weights. But for the slightly longer text in your visualizations (like descriptions, notes, or annotations) the regular or medium font weights are often the easiest to read. Use bold text only for titles or to emphasize a few words in annotations.
Here are two examples, both by The Washington Post:
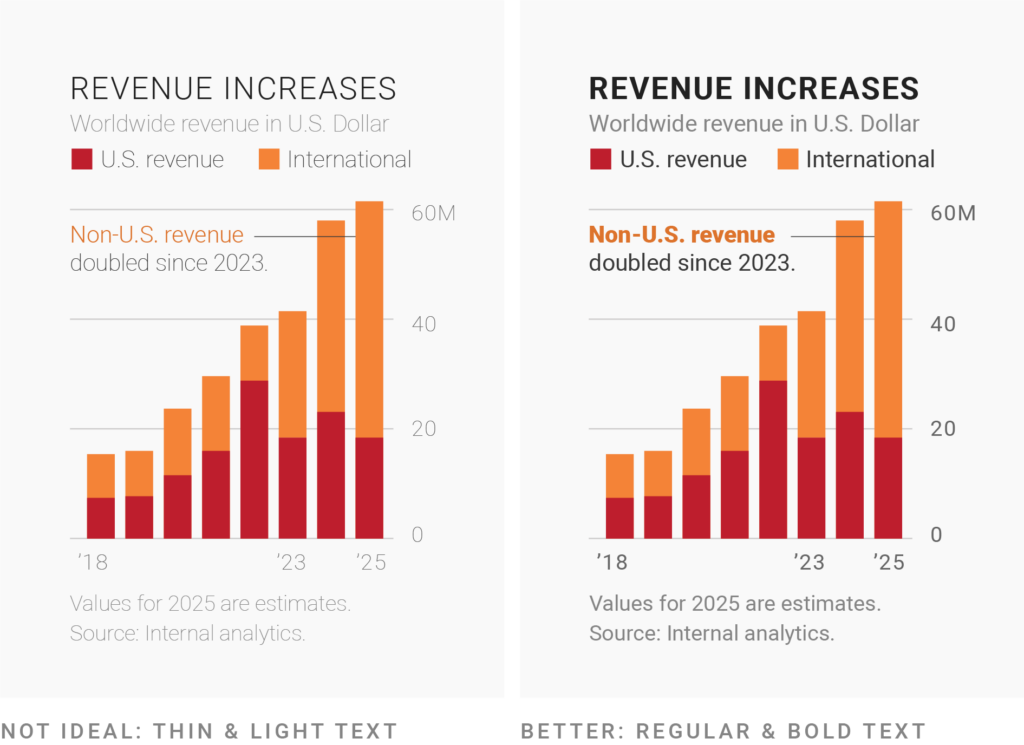
Text set in a thin or light font weight has such delicate strokes that it looks as if it’s set in a brighter color (e.g. gray instead of black). If you’re trying to make text look less important while getting around a restrictive color contrast ratio, thinner weights might sound like a great solution.
But as you can see in the example above, thin font weights are also really, really hard to read. Only use them in a high-contrast color and in big sizes (often, that means for titles only).
👉 Read more: Do’s and Don’ts of Using Light Typefaces by Anthony Tseng

Narrow (also called condensed) fonts need less space, so it’s tempting to use them in a data visualization. The problem: The less space a character gets, the harder it is to read. Narrow fonts are more difficult to decipher than normal-width fonts. Very wide fonts like Montserrat have the opposite problem: They’re easy to read but use too much space.
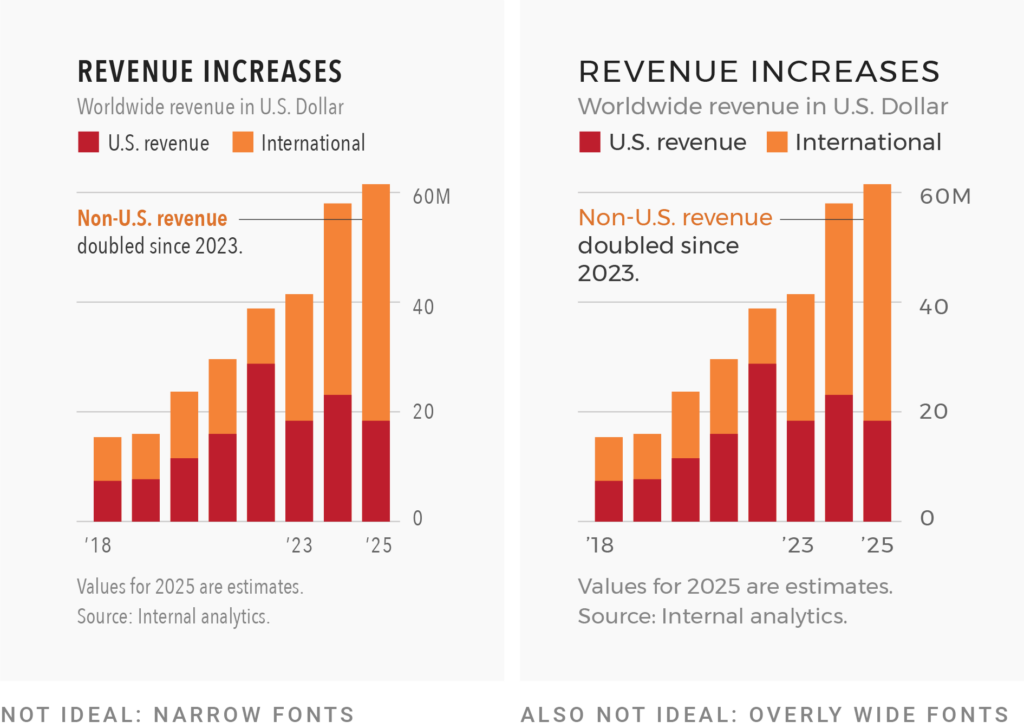
Most newsrooms use normal-width fonts. I can only think of two that diverge from that norm, NPR and The Wall Street Journal:


It’s hard to use narrow typefaces elegantly. They quickly look like a slightly retro, cramped compromise that communicates, “We wanted to remain a certain font size but couldn’t make the design work for a normal-width font.” But often, normal-width text in a smaller size is as or even more readable than bigger text in a narrow typeface:
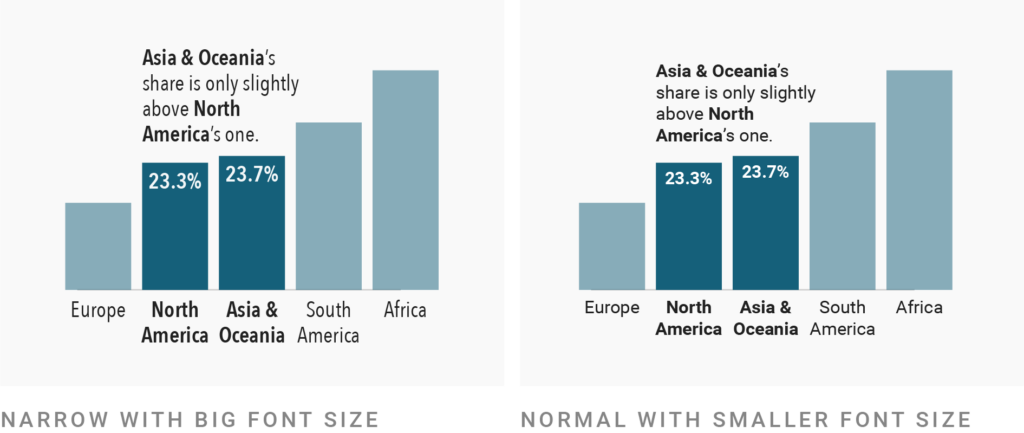
But there are beautiful examples too. The 2007 Feltron report uses an extremely narrow typeface and makes it work by setting only really big text:

👉 Read more: Condensed fonts: The good, the bad, the ugly by Carrie Cousins
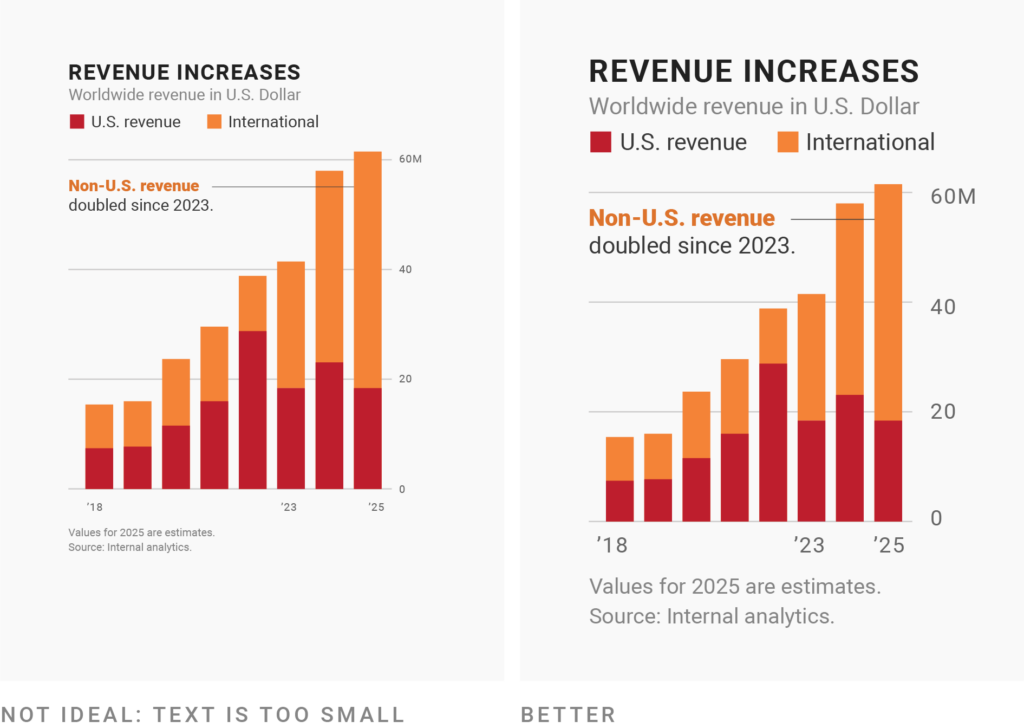
So far, we covered which typefaces and fonts we should choose for our data visualizations. Let’s now talk about how and when we can customize them by making them bigger or smaller, giving them a higher- or lower-contrast color, and making them uppercase. First, the font size:
The Web Content Accessibility Guidelines (WCAG) have a lot of opinions on how to make the web more accessible and readable. It’s likely that your organization tries to comply with these guidelines. So what do they advise your minimum font size to be? Turns out, they don’t give a clear answer. That’s because the readability of a typeface depends not just on font size, but also on font family, capitalization, letter spacing, and text color:

Text annotations in Datawrapper use a default 14px for Roboto. Depending on the font family, everything below 12px will likely be too small. If you’re not sure, ask a friend or coworker to help you make the decision.
👉 Read more: Accessible Font Sizing, Explained by Andrés Galante

While the WCAG can’t give us a minimum font size, they do mention a minimum contrast ratio. Use a contrast checker to make sure your colors comply. For more explanations and a more critical view on the topic, read our article It’s time for a more sophisticated color contrast check for data visualizations.

Uppercase (“all caps”) text is harder to read than “sentence case” text that has both uppercase and lowercase letters. That’s because the shapes of letters help people to recognize words – and in uppercase, the whole text looks like a rectangle. That said, uppercase text can look tidier precisely because of the missing up and downs.
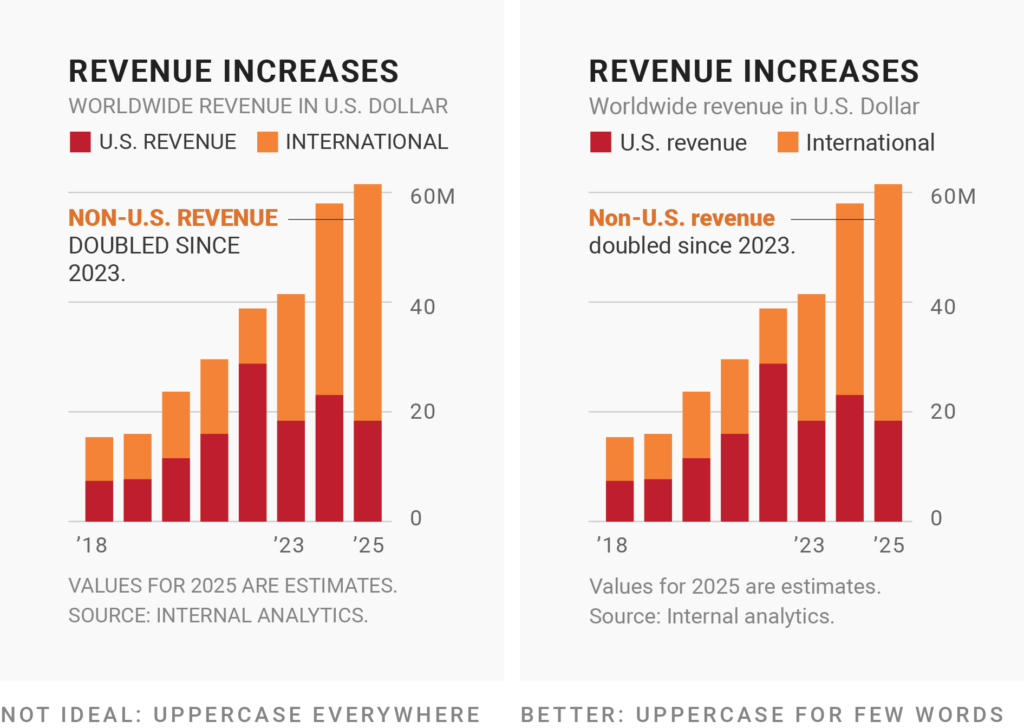
As soon as you transform your text to uppercase, you’ll find that the text becomes wider than it was in normal sentence case — while also looking a bit dense:

But there are a few tricks to adjust that:
letter-spacing. Here’s the full process:

The result is an uppercase text that’s similar in length and letter stroke width to the lowercase version:

If you want to use uppercase text in your data visualization, limit it to just a few words. Because uppercase words look so important and neat, they communicate: “I’m not like the other elements here.” Often they’re used for labels or headlines, e.g. filter elements, (a few) category labels in tooltips, group labels, axis labels, or header text in tables:


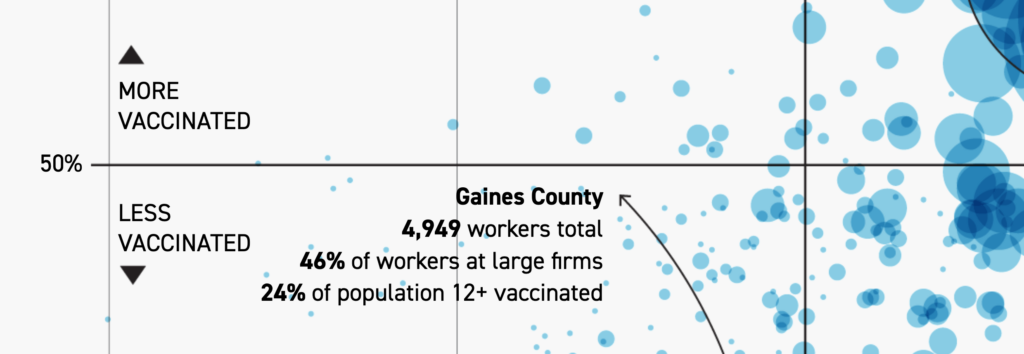

The most common place you’ll find uppercase text in data visualizations is region labels (e.g. for countries or states) in maps. Here, uppercase text is often more letter-spaced than when used in charts:
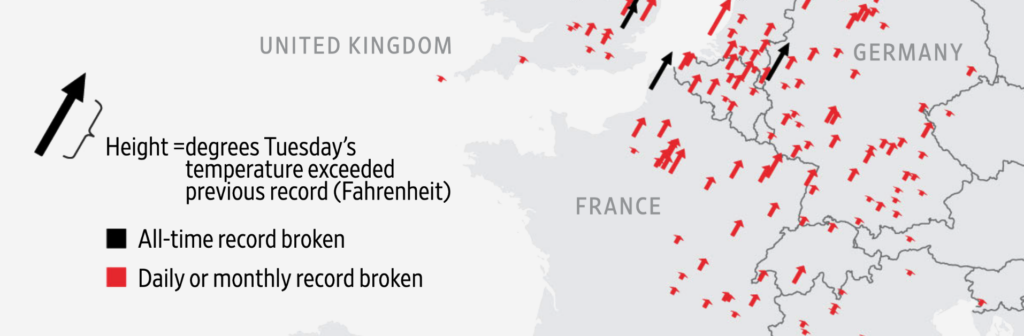
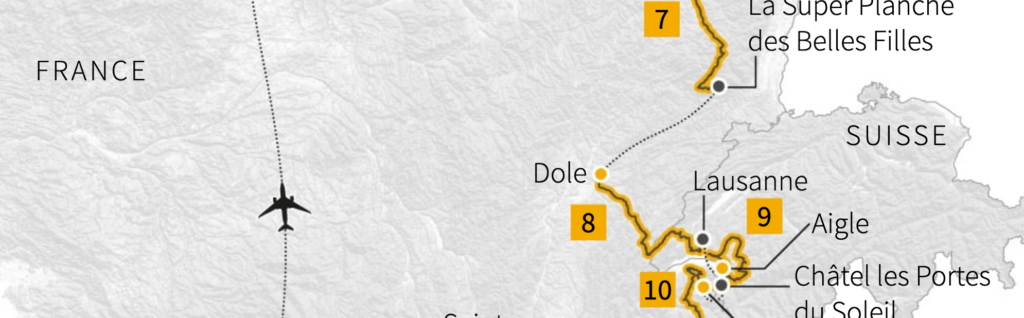


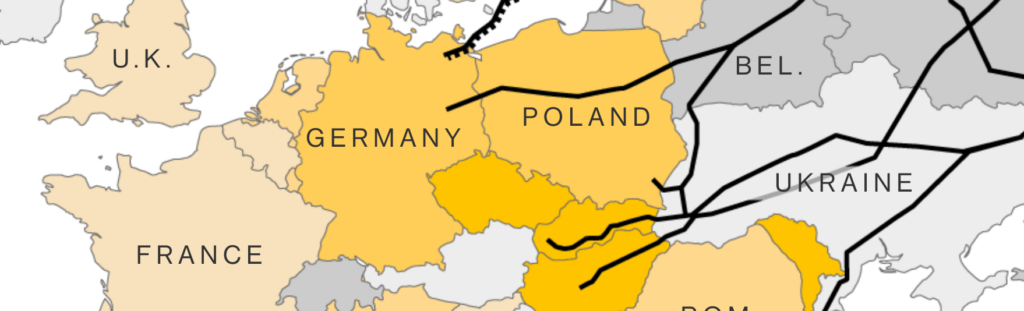
There’s no need to retype with capslock on to create uppercase text — most graphics software has a button for that. In Datawrapper locator maps, too, you can make text uppercase and letter-space your markers with the click of a button.
👉 Read more: UPPERCASE in UI Design by Bradley Nice
I hope this article was helpful! If there’s any essential advice I missed, leave it in the comments or write to me at lisa@datawrapper.de. I’m looking forward to hearing from you.


Comments